
Over the past month, we decided to implement DataHub at our organization as the central repository for storing and managing metadata about our data model. We installed DataHub via Plural on a Kubernetes Cluster in our cloud account.
The data model we wanted to build a catalog for primarily exists in Amazon Redshift and is orchestrated by Apache Airflow. We use dbt core within Airflow as the ‘T’ layer of our ETL. To run dbt core in Airflow, we use the Astronomer Cosmos package. In this transformative layer, we:
- Write metadata descriptions
- Complete data quality checks
- Normalize our data
These are vital steps that should exist in our DataHub catalog. DataHub offers a dbt ingestion integration that makes this possible. In this guide, we’ll specifically discuss how we automate this metadata ingestion.
The Needed Files
For the DataHub dbt integration to work correctly, we need the following files generated by dbt into an S3 bucket:
- manifest.json
- catalog.json
- sources.json
- run_results.json
To generate these, we can run a dbt source freshness command. In Airflow, we can use inheritance to override the DbtBaseLocalOperator and create a custom operator that accomplishes this:
# dags/utils/dbt/custom_docs.py
from __future__ import annotations
from typing import Any
import logging
import os
from cosmos.operators.local import DbtDocsLocalOperator, DbtLocalBaseOperator
logger = logging.getLogger(__name__)
class DbtFreshnessLocalOperator(DbtLocalBaseOperator):
"""
Executes the `dbt source freshness` command
Use the `callback` parameter to specify a callback function to run after the command completes.
"""
ui_color = "#8194E0"
def __init__(self, **kwargs: Any) -> None:
super().__init__(**kwargs)
self.base_cmd = ["source", "freshness"]
class DbtFreshnessS3LocalOperator(DbtFreshnessLocalOperator):
"""
Executes `dbt source freshness` command and upload to S3 storage. Returns the S3 path to the generated documentation.
:param aws_conn_id: S3's Airflow connection ID
:param bucket_name: S3's bucket name
:param folder_dir: This can be used to specify under which directory the generated DBT documentation should be
uploaded.
"""
ui_color = "#FF9900"
def __init__(
self,
aws_conn_id: str,
bucket_name: str,
folder_dir: str | None = None,
**kwargs: str,
) -> None:
"Initializes the operator."
self.aws_conn_id = aws_conn_id
self.bucket_name = bucket_name
self.folder_dir = folder_dir
super().__init__(**kwargs)
# override the callback with our own
self.callback = self.upload_to_s3
def upload_to_s3(self, project_dir: str) -> None:
"Uploads the generated documentation to S3."
logger.info(
'Attempting to upload generated docs to S3 using S3Hook("%s")',
self.aws_conn_id,
)
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
target_dir = f"{project_dir}/target"
hook = S3Hook(
self.aws_conn_id,
extra_args={
"ContentType": "text/html",
},
)
logger.info("Uploading %s to %s", "sources.json", f"s3://{self.bucket_name}/sources.json")
key = f"{self.folder_dir}/sources.json" if self.folder_dir else "sources.json"
hook.load_file(
filename=f"{target_dir}/sources.json",
bucket_name=self.bucket_name,
key=key,
replace=True,
)
class DbtDocsS3LocalOperator(DbtDocsLocalOperator):
"""
Executes `dbt docs generate` command and upload to S3 storage. Returns the S3 path to the generated documentation.
:param aws_conn_id: S3's Airflow connection ID
:param bucket_name: S3's bucket name
:param folder_dir: This can be used to specify under which directory the generated DBT documentation should be
uploaded.
"""
ui_color = "#FF9900"
def __init__(
self,
aws_conn_id: str,
bucket_name: str,
folder_dir: str | None = None,
**kwargs: str,
) -> None:
"Initializes the operator."
self.aws_conn_id = aws_conn_id
self.bucket_name = bucket_name
self.folder_dir = folder_dir
super().__init__(**kwargs)
# override the callback with our own
self.callback = self.upload_to_s3
def upload_to_s3(self, project_dir: str) -> None:
"Uploads the generated documentation to S3."
logger.info(
'Attempting to upload generated docs to S3 using S3Hook("%s")',
self.aws_conn_id,
)
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
target_dir = f"{project_dir}/target"
hook = S3Hook(
self.aws_conn_id,
extra_args={
"ContentType": "text/html",
},
)
for filename in ["manifest.json", "catalog.json", "run_results.json"]:
logger.info("Uploading %s to %s", filename, f"s3://{self.bucket_name}/{filename}")
key = f"{self.folder_dir}/{filename}" if self.folder_dir else filename
hook.load_file(
filename=f"{target_dir}/{filename}",
bucket_name=self.bucket_name,
key=key,
replace=True,
)
Using Airflow to Run the Operators
Now that we’ve created our custom operator, we can use it in our Airflow DAG to generate the files that DataHub needs (and upload them to an S3 bucket):
# dags/dbt_docs.py
from datetime import datetime
from airflow import DAG
from cosmos import ProfileConfig
from cosmos.profiles.redshift.user_pass import RedshiftUserPasswordProfileMapping
from dags.utils.dbt.custom_docs import DbtFreshnessS3LocalOperator
'''other targets can be used instead of Redshift - for more information,
visit Cosmos's official docs here: https://astronomer.github.io/astronomer-cosmos/profiles/index.html'''
redshift_profile = RedshiftUserPasswordProfileMapping(
conn_id="redshift_default",
profile_args={
"dbname": "your_db_name",
"schema": "your_default_dbt_schema"
}
)
aws_bucket = "<your-s3-bucket-name>"
with DAG(
dag_id="dbt_docs",
start_date=datetime(2023, 10, 30),
schedule=None,
catchup=False,
max_active_runs=1,
tags=["datahub"],
):
DbtDocsS3LocalOperator(
task_id="generate_dbt_docs",
aws_conn_id="aws_default", # Airflow Conneciton to access bucket
bucket_name=aws_bucket, # AWS Bucket where you want the files
profile_config=ProfileConfig(
profile_name="your_dbt_project_name",
target_name="cosmos_target",
profile_mapping=redshift_profile,
),
)
DbtFreshnessS3LocalOperator(
task_id="generate_dbt_freshness",
aws_conn_id="aws_default", # Airflow Connection to access bucket
bucket_name=aws_bucket, # AWS Bucket where you want the files
profile_config=ProfileConfig(
profile_name="your_dbt_project_name",
target_name="cosmos_target",
profile_mapping=redshift_profile
),
)Creating the dbt Integration in DataHub
Now that our files exist in S3, we can create a DataHub ingestion recipe to retrieve them. Before doing so, add your AWS creds to your DataHub secrets so they are callable in the recipe:
source:
type: dbt
config:
manifest_path: 's3://your-s3-bucket-name/manifest.json'
catalog_path: 's3://your-s3-bucket-name/catalog.json'
sources_path: 's3://your-s3-bucket-name/sources.json'
test_results_path: 's3://your-s3-bucket-name/run_results.json'
target_platform: redshift
aws_connection:
aws_access_key_id: '${AWS_ACCESS_KEY}'
aws_secret_access_key: '${AWS_SECRET_ACCESS_KEY}'
aws_region: '${AWS_DEFAULT_REGION}'Add a schedule to your DataHub dbt ingestion that runs more frequently than the Airflow DAG generating the files, and voila, you have successfully automated the metadata ingestion from dbt core (running in Airflow via Cosmos) into DataHub.
The End Result
As you add metadata descriptions and data quality checks in dbt, you will see them populate as the metadata gets refreshed.
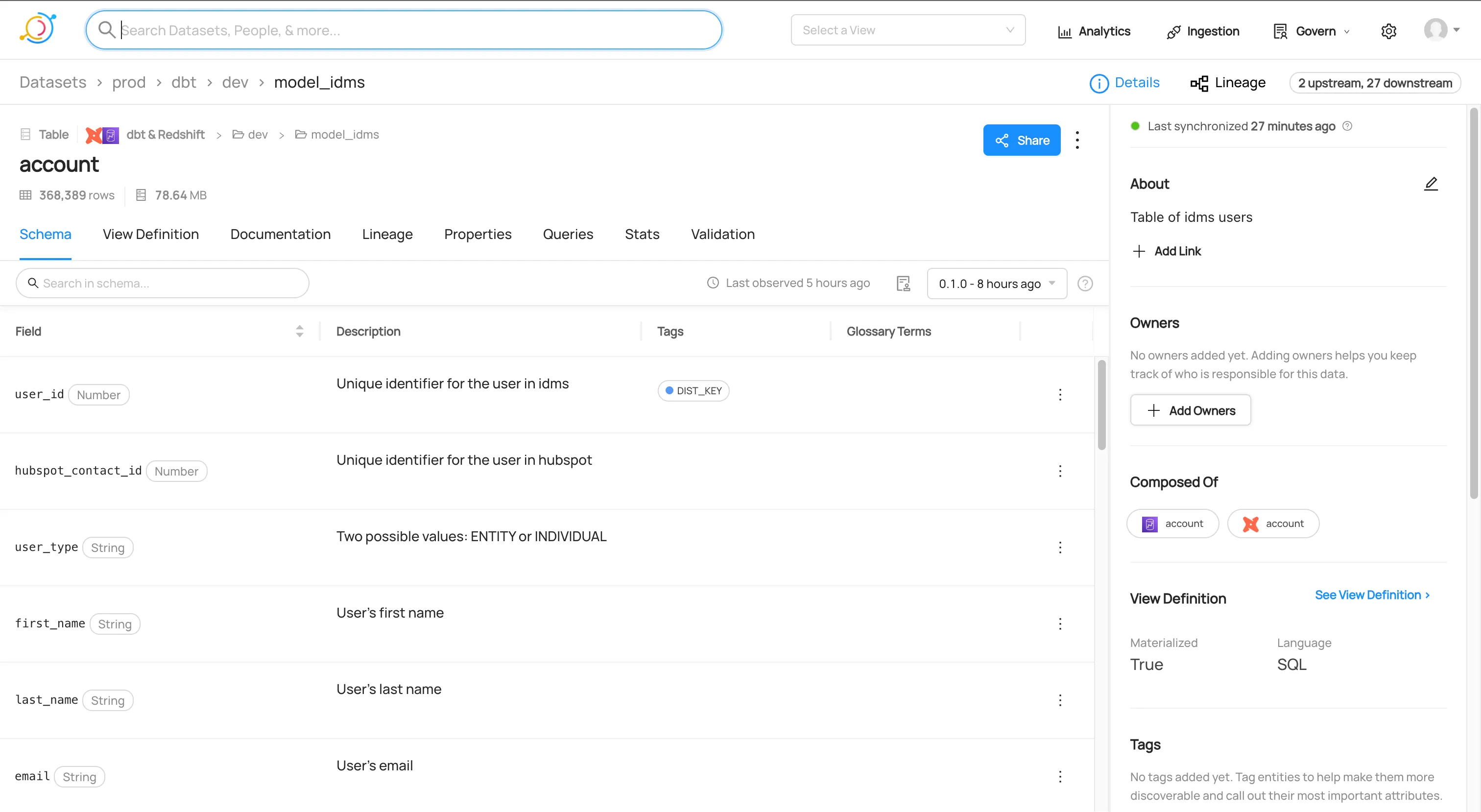
Metadata
An example of metadata descriptions written into our dbt project:
Lineage
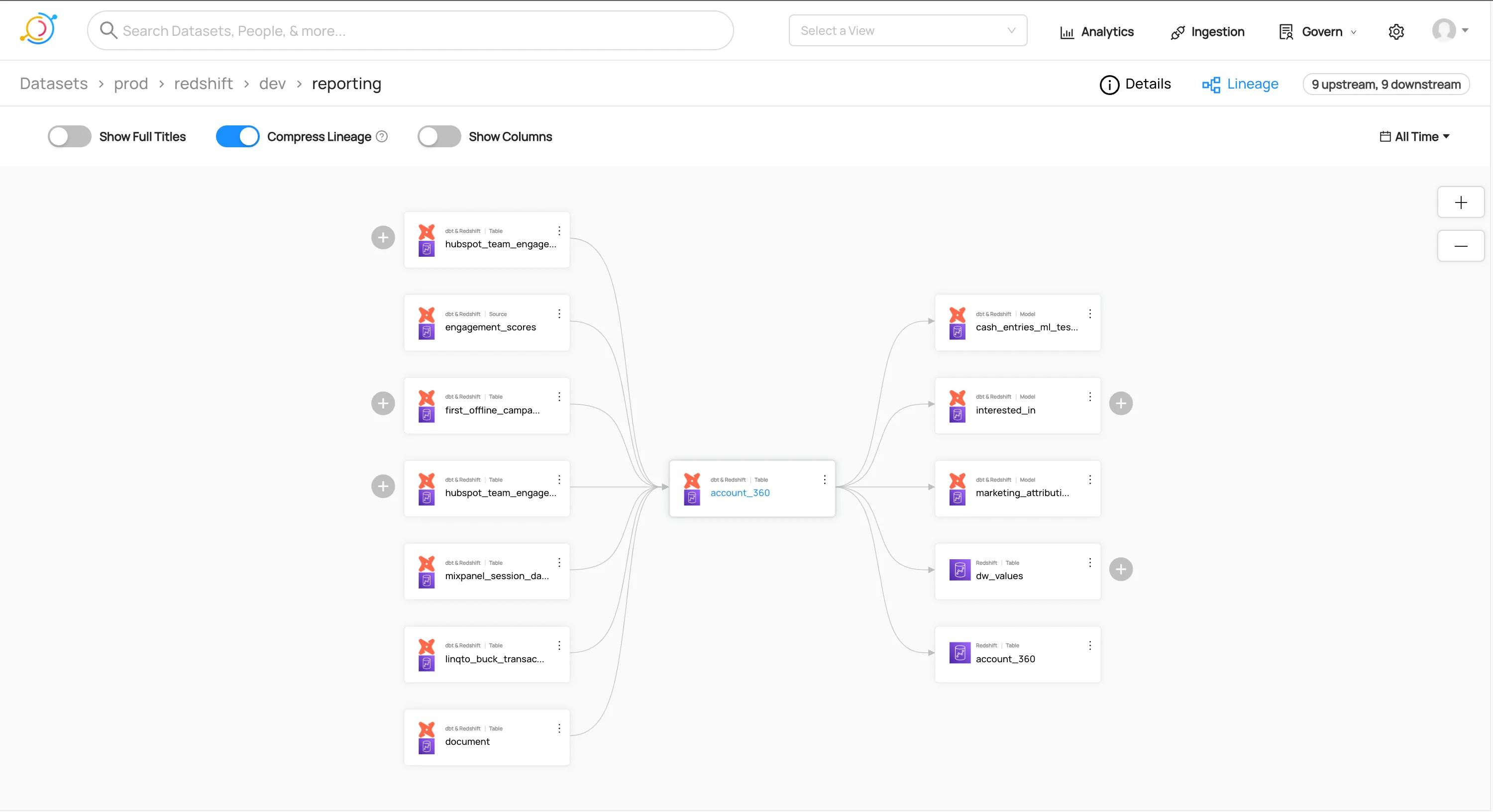
An example of upstream and downstream node relations from our dbt project:
Need Help?
If you are looking to implement a Data Catalog or are in search of other Data Consultancy services for your business, please reach out to us on Discord or submit a service request here.