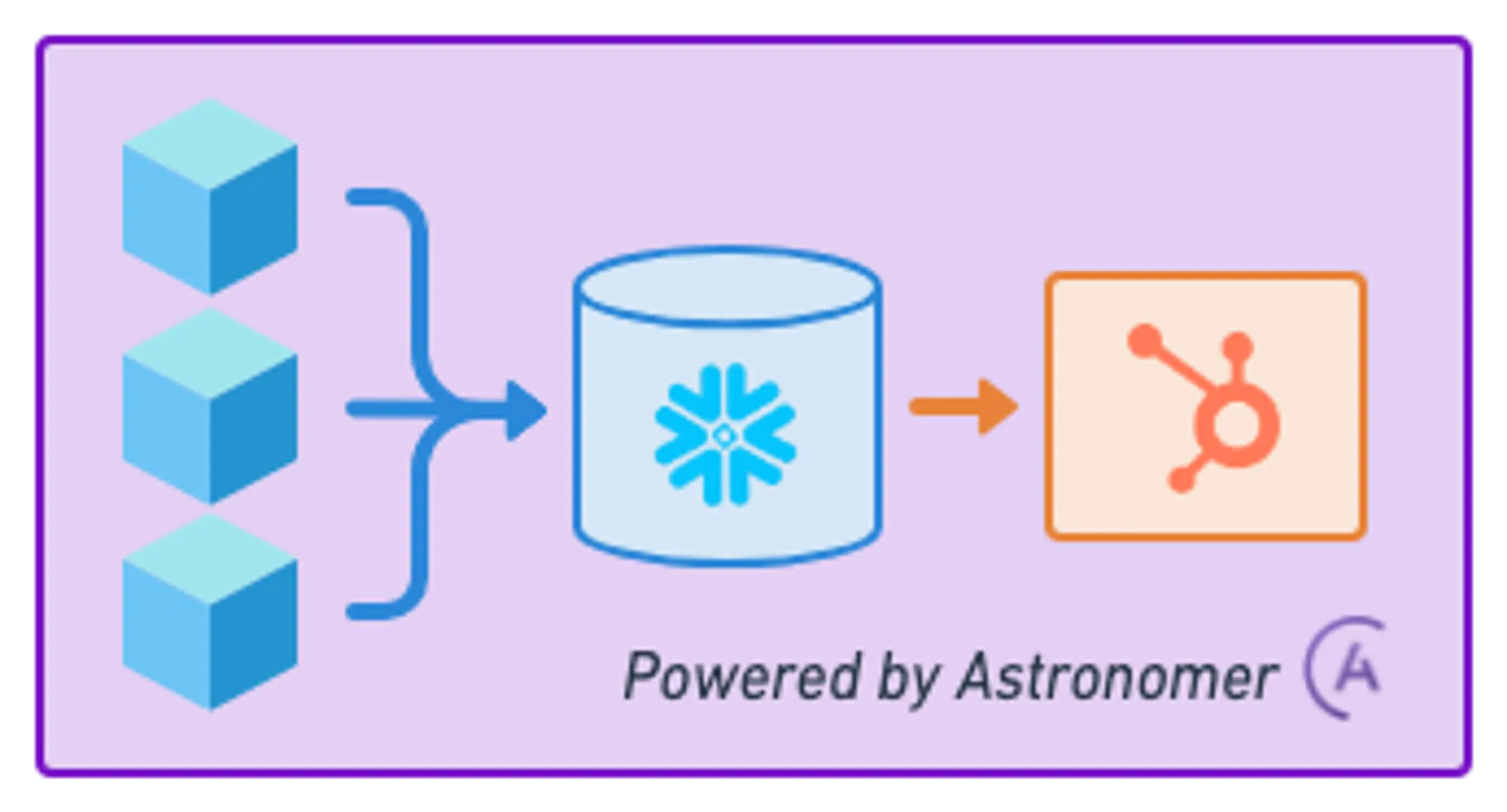
Since I started working with data pipelines, one challenge has remained constant: getting analytical data back into operational systems effectively. Sure, we can build fancy dashboards and reports, but what happens when your sales team needs that enriched customer data directly in HubSpot? That’s where reverse ETL comes in, and in this post I’ll share how we built a production-grade pipeline that syncs data from Snowflake to HubSpot using Apache Airflow.
The Real World Problem
Initially, we were using a third-party reverse ETL service which worked well for our basic needs. The solution was cost-effective until we hit their data volume caps. When they proposed a minimum 260% price increase for our growing data needs, we had to reevaluate. After analyzing the value proposition and our internal capabilities, we decided to build rather than buy. This decision not only saved us significant costs but also gave us more control over our data pipeline.
However, when building your own reverse ETL pipelines, you’ll face these types of headaches:
- Dealing with strict API rate limits in CRM & Marketing tools
- Meeting marketing team’s needs for frequent data updates
- Managing growing volumes of customer data
- Maintaining reliability to avoid missing or stale data in HubSpot
At Linqto, we solved these challenges by building a scalable reverse ETL pipeline using Apache Airflow. Here’s how we did it.
The Architecture
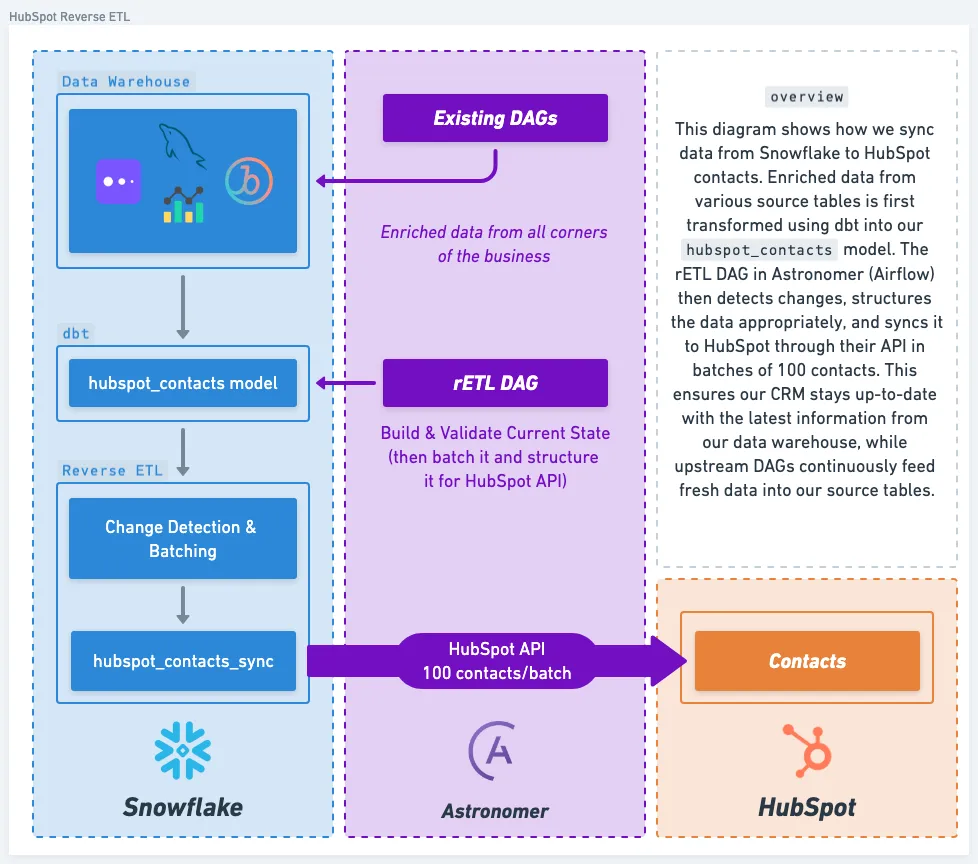
Instead of reinventing the wheel, we leveraged tools we already had in our stack:
- Apache Airflow (hosted on Astronomer): Handles all our orchestration and makes parallel processing a breeze
- Snowflake: Does the heavy lifting for change detection right in the warehouse
- Custom HubSpot Hook: Manages API interaction with built-in rate limiting (trust me, you’ll need this)
- Dynamic Task Generation: Automatically scales based on your data volume
The real magic happens in how these pieces work together. Let me show you each component and share what we learned building this in production.
The Building Blocks
1. Configuration as Code
First things first – we needed a clean way to define our sync mappings. Here’s what we came up with:
reverse_etls = {
"hubspot_contacts": {
"schema": "retl",
"current_state_tbl": "hubspot_contacts",
"sync_table_name": "hubspot_contacts_sync",
"unique_id_col": "contact_id",
"batch_size": 100,
"column_mappings": [
{"destination_name": "engagement_score", "snowflake_name": "engagement_score"},
{"destination_name": "capital_allocation", "snowflake_name": "capital_allocation"},
# ... additional mappings ...
],
}
}This configuration-driven approach has saved us countless headaches. It makes changes simple and keeps our code clean. Plus, when the marketing team needs new fields synced, we just update the mappings and deploy.
2. Smart Change Detection
Here’s something I learned the hard way: you don’t want to sync everything all the time. We built a clever change detection system right in Snowflake using a Python UDF:
create or replace function generate_retl_payload(curr_payload STRING, prev_payload STRING)
returns STRING
language python
runtime_version = '3.8'
handler = 'compare_payloads'
as
$$
import json
def compare_payloads(curr_payload: str, prev_payload: str) -> str:
curr_obj = json.loads(curr_payload) if curr_payload else {}
prev_obj = json.loads(prev_payload) if prev_payload else {}
result = {}
# Only include changed fields
for key, value in curr_obj.items():
if key not in prev_obj or prev_obj[key] != value:
result[key] = value
return json.dumps(result)
$$;This function is pretty slick – it only includes fields that have actually changed in the sync payload. No more wasting API calls on unchanged data.
3. Dynamic Parallel Processing
One of the coolest things we built is dynamic task generation based on data volume. Here’s how it works:
@task
def determine_total_batches(
reverse_etl_config: dict,
target_x: int = 15,
airflow_dynamic_task_limit: int = 512
):
total_records = get_record_count()
total_api_calls = math.ceil(total_records / 100) # HubSpot's batch size
if total_api_calls <= 32:
return [1] # Single batch for small datasets
parallel_tasks = min(
math.ceil(total_api_calls / target_x),
airflow_dynamic_task_limit
)
return range(1, parallel_tasks + 1)This code automatically figures out how many parallel tasks we need based on the data volume. For small syncs, it runs everything in one go. For larger datasets, it splits things up to maximize throughput while respecting API limits.
5. The Sync SQL Template
The heart of our sync operation is this SQL template. It detects changes and prepares data for syncing:
insert into {{ params.sync_table_name }} (updated_at, {{ params.unique_id_col }}, payload, batch_number)
with curr_state_obj as (
select
{{ params.unique_id_col }},
to_json(
object_construct(
{% for col in params.column_mappings %}
'{{ col.destination_name }}', {{ col.snowflake_name }}{% if not loop.last %},{% endif %}
{% endfor %}
)
) as curr_payload
from {{ params.current_state_tbl }}
where {{ params.unique_id_col }} is not null
),
prev_state_obj as (
-- get the most recent sync state for each attribute
select
last_values.{{ params.unique_id_col }},
to_json(object_agg(last_values.prev_k, last_values.prev_v)) as prev_payload
from (
select
st.{{ params.unique_id_col }},
f.key as prev_k,
f.value as prev_v
from {{ params.sync_table_name }} as st,
table(flatten(input => parse_json(st.payload::STRING))) as f
qualify row_number() over (partition by st.{{ params.unique_id_col }}, f.key order by st.updated_at desc) = 1
) as last_values
group by last_values.{{ params.unique_id_col }}
)
select
current_timestamp as updated_at,
curr_state_obj.{{ params.unique_id_col }},
generate_retl_payload(curr_state_obj.curr_payload, prev_state_obj.prev_payload) as payload,
(row_number() over (order by curr_state_obj.{{ params.unique_id_col }}) - 1) % {{ params.batch_size }} + 1 as batch_number
from curr_state_obj
left join prev_state_obj on prev_state_obj.{{ params.unique_id_col }} = curr_state_obj.{{ params.unique_id_col }}
where
curr_state_obj.curr_payload != prev_state_obj.prev_payload
and payload != '{}';This template does some pretty clever things:
- Creates JSON payloads from your current data state
- Compares them with the previous sync state
- Only processes records that have actually changed
- Assigns batch numbers for parallel processing
I love how Snowflake’s JSON handling makes this so clean - no need for complex string manipulation or external processing.
4. Bulletproof API Integration
After getting rate-limited one too many times, we built a HubSpot hook that handles all the annoying parts of API interaction:
class HubSpotHook(BaseHook):
def batch_action(self, action: str, object_type: str, data: dict):
while True:
try:
response = requests.post(
url=f"{self.base_url}/crm/v3/objects/{object_type}/batch/{action}",
headers=self._get_authorized_headers(),
data=json.dumps(data)
)
response.raise_for_status()
return response.json()
except requests.exceptions.HTTPError as e:
if "rate limit" in str(e):
time.sleep(10)
else:
raiseThe built-in retries and rate limit handling have been lifesavers in production.
Putting It All Together
Here’s what our final DAG looks like:
with DAG(
dag_id="retl",
schedule="@daily",
catchup=False,
):
# Prepare data with dbt
dbt_modeling = LinqtoDbtTaskGroupSnowflake(
model="retl",
operator_args={"full_refresh": "{{ params.dbt_full_refresh }}"}
)
# Key decision point: only run syncs in PROD
trigger_retl = EmptyOperator(task_id="trigger_retl")
skip_retl = EmptyOperator(task_id="skip_retl")
# Branch based on environment
dbt_modeling >> env_check("trigger_retl", "skip_retl") >> [trigger_retl, skip_retl]
# Generate sync batches
configure_batch_numbers = determine_total_batches(
reverse_etl_config=reverse_etls["hubspot_contacts"]
)
# Run the initial sync to detect changes
hubspot_contacts_sync = LinqtoSnowflakeOperator(
task_id="hubspot_contacts_sync",
sql="retl/attr_sync_template.sql",
params=reverse_etls["hubspot_contacts"]
)
# Update batch numbers for optimal distribution
update_batch_numbers = LinqtoSnowflakeOperator(
task_id="set_dynamic_batch",
sql="retl/set_dynamic_batch.sql",
params=reverse_etls["hubspot_contacts"]
)
# Execute HubSpot updates in parallel
update_contacts = batch_update_hubspot_contacts.partial(
reverse_etl_config=reverse_etls["hubspot_contacts"]
).expand(batch_number=configure_batch_numbers)
# Define the complete flow
trigger_retl >> hubspot_contacts_sync
hubspot_contacts_sync >> configure_batch_numbers >> update_batch_numbers >> update_contacts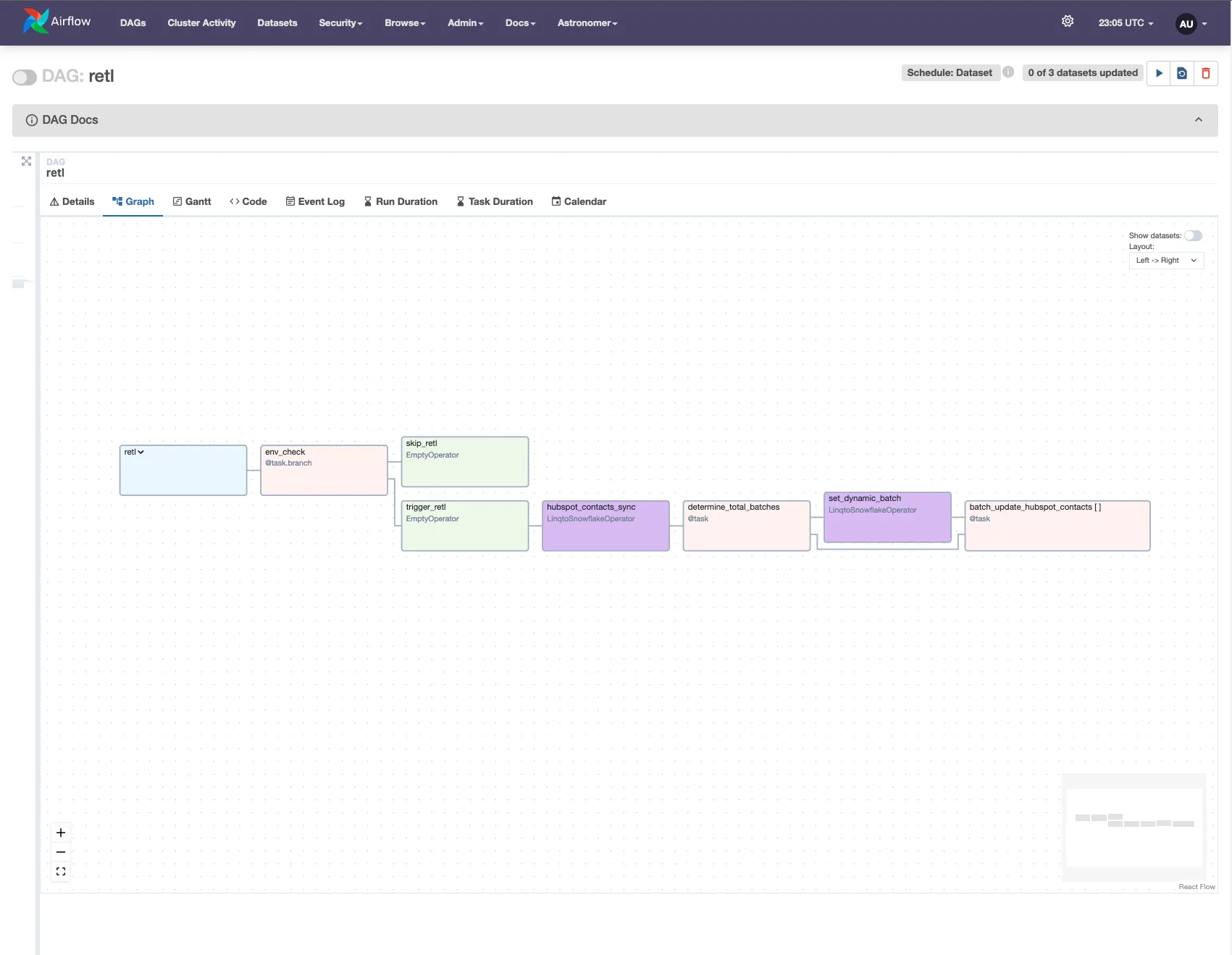
Lessons Learned
Building this in production taught us a few key things:
- Always Detect Changes First: Don’t waste API calls on unchanged data
- Batch Size Matters: Finding the sweet spot between parallelization and API limits takes experimentation
- Error Handling is Key: Comprehensive retry logic saved us many times
- Monitor Everything: Track sync statistics and API response times religiously
- Keep Configuration Flexible: Business needs change; your code should adapt easily
Wrapping Up
Building a reliable reverse ETL pipeline isn’t just about moving data – it’s about understanding API limitations, handling edge cases, and creating something that scales with your business. By combining Airflow’s orchestration capabilities with Snowflake’s processing power, we’ve built a system that efficiently syncs data while respecting API constraints.
If you’re looking to build a reverse ETL pipeline for your business, I hope this guide has given you some ideas. If you have any questions or feedback, please use my social links to reach out.