
If there is one universal truth about data, it grows and expands. Anyone who has ever built data models or developed a database architecture in a data warehouse understands that one model will become five, and the intricacies of your company’s data are convoluting what was once a simple star/snowflake schema.
Metaphorically, you can envision this data growth like a tree or a bush. Just as a tree needs trimming to ensure branches don’t reach your neighbor’s yard or dangerously hang over your home waiting to break, a data model should be regularly pruned, maintained, documented, and tested before it becomes too unruly to manage.

Introducing SDF
However, this “growth” isn’t always a bad thing. Data growth typically infers company growth, which may correlate to profits. So, it’s not that your data shouldn’t grow; it’s more about how you get it to grow healthily. The tool that has helped my data models thrive is Semantic Data Fabric (SDF). This blog post discusses how SDF enforces healthy data growth via Lineage, Contracts, and Classifiers. But before jumping into these features, let’s talk more about SDF.
SDF is a compiler and build system leveraging static analysis to examine SQL code at a warehouse scale comprehensively. Data developers use SDF to identify problematic code patterns like security vulnerabilities and privacy leaks. By evaluating all queries in any dialect, SDF and its Code Contracts become robust solutions for org-scale data privacy, quality, and governance.
Lineage
Anyone who builds anything off a data model, whether visualizations, reverse ETLs, Machine Learning models, or other data processes, has probably experienced some form of paralysis to change a data model because they fear they’ll break something downstream. Data practitioners may hesitate to combine new tables with old ones and repurpose or delete columns as they build their products. This hesitation can lead to bad growth of our data model tree. Alternatively, if you give data practitioners a view of what their changes could impact, they’ll be more likely to modify existing models than to create new ones. SDF provided column-level lineage to understand downstream column/table references.
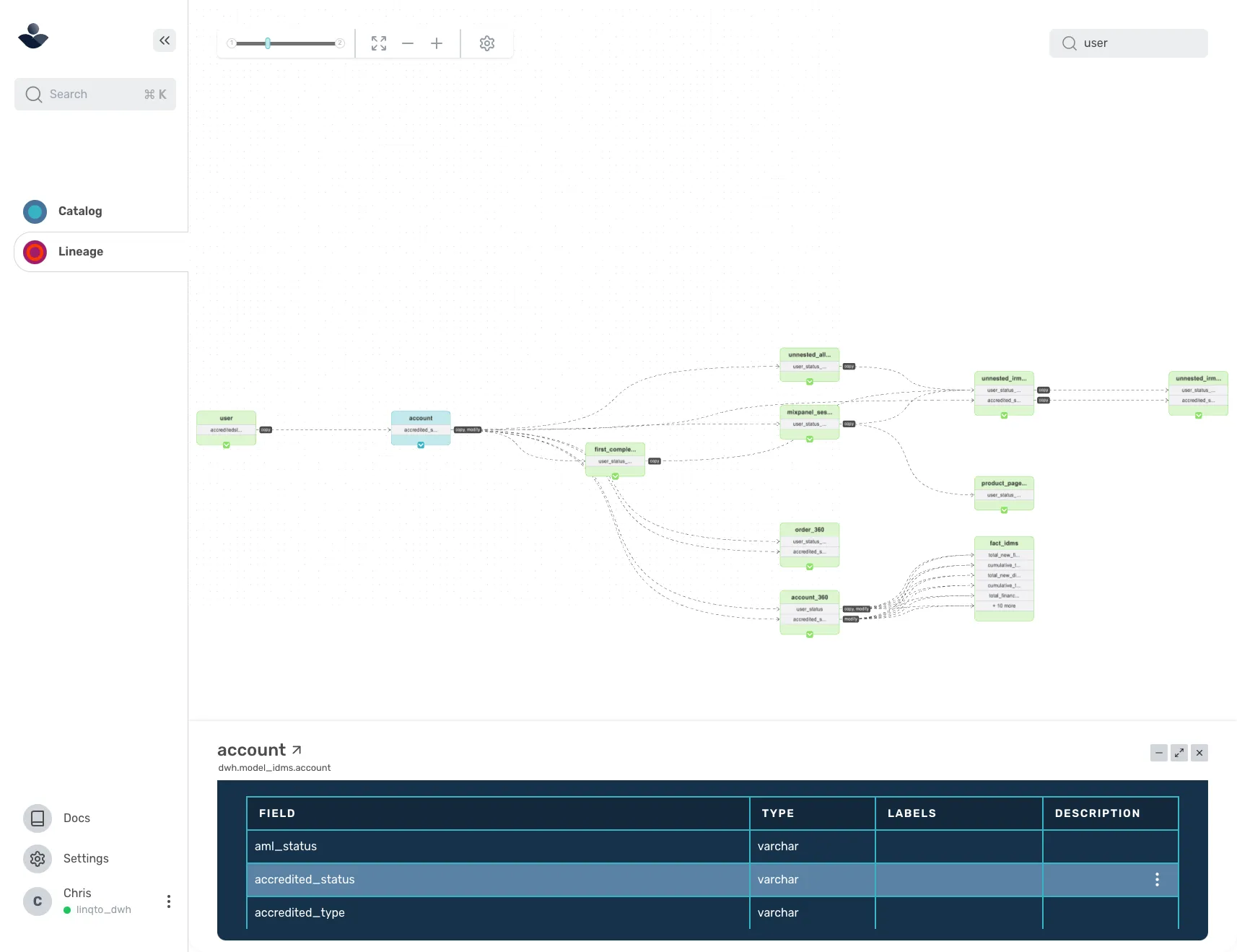
Contracts
As you build your desired architecture in your Data Warehouse, you’ll typically find that the data team should follow the rules for healthy data growth. For me, there were some general rules about our data model and snowflake schema design:
- We load raw, untransformed data into schemas pre-appended with
sor_ - We copy
sor_data into schemas prefixed withmodel_. We document and test tables and columns, standardize column naming, convert date fields to a unified time zone, and redact PII. - We maintain a prod database and a dev database. We use dev to test SQL transformations and prod feeds downstream visualizations, reverse ETLs, and Machine Learning processes. While dev replicates prod, we should never reference dev once we productize SQL.
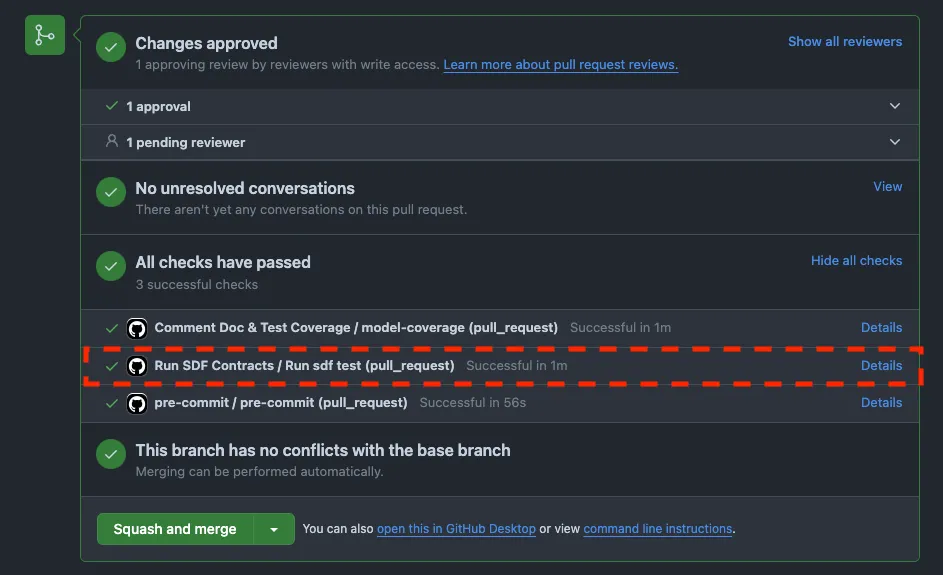
Before we adopted SDF, we reviewed changes to the data model through a process on GitHub, and it was our responsibility to enforce these rules during the review. Now, with SDF, we build Code Contracts that verify the presence of specific properties we aim to ensure. Thus, we integrate all these rules into a Continuous Integration (CI) Pipeline that activates when someone opens a Pull Request to change the data model. The CI will pass if the submission adheres to the rules or fails in case of violations.
Code Contracts are simply small SQL queries that run against an information schema that SDF generates. So, for us, we could write a code contract in SQL that enforced references to our dev database:
select table_ref
from sdf.information_schema.tables
where dependencies ilike '%dwh_dev.%'If the query returns results when running the sdf test command, the CI check fails, and we know the Pull Request isn’t ready. Otherwise, the CI check passes:
Classifiers
As companies comply with privacy laws and build their reputation and trust, Personally Identifiable Information (PII) is usually of utmost concern. Knowing what PII exists in your data warehouse and who has access to that information is critical. Organizations should only collect and store data that is directly relevant and necessary to accomplish their purpose. SDF Classifiers are an excellent option for identifying, annotating, and propagating PII in your data warehouse.
Classifiers enable you to “annotate” or “tag” a column with metadata, applying this “tag” to all downstream references to that column. Thus, when we introduced a new data source and loaded it into one of our sor_ schemas, we reviewed the data and tagged any column potentially containing PII with classifiers. As we develop SQL models, the system automatically applies those annotations to new downstream references.
classifier:
name: PII
labels:
- name: legal_name
---
table:
name: dwh.sor_idms.user
columns:
- name: firstname
classifiers:
- PII.legal_name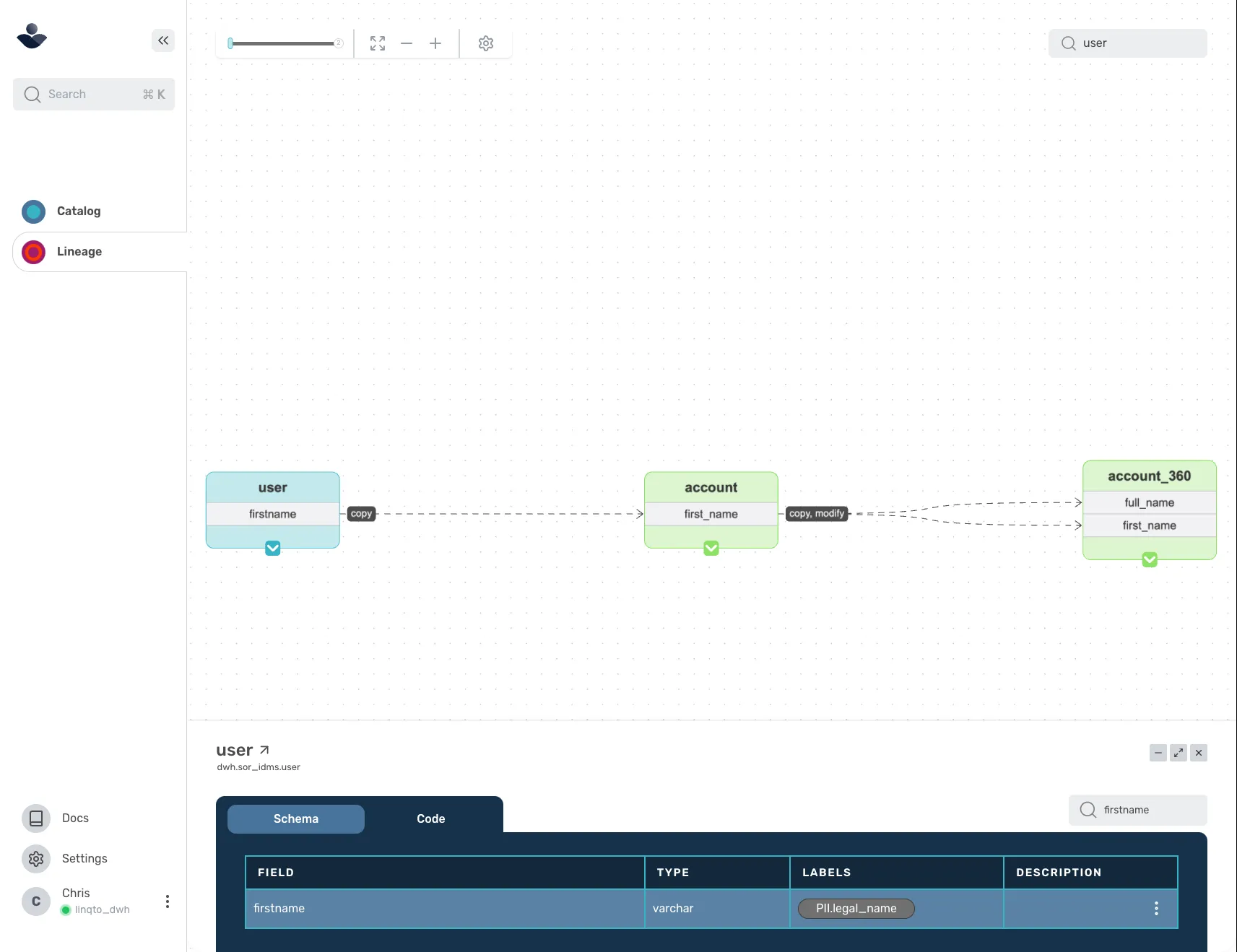
You can use classifiers in your code contracts to actively check and prevent PII from being referenced in unauthorized parts of your data warehouse!
Conclusion
In data management, growth is an inevitable companion to innovation and expansion. This blog post illuminated the complex journey of data models within a data warehouse, underscoring the crucial role of tools like Semantic Data Fabric (SDF) in promoting healthy, manageable growth.
SDF, with its best-in-class features, equips data practitioners with the means to navigate the intricacies of data governance. It ensures that data models support company advancement while maintaining compliance and safeguarding sensitive information. By automating best practices and reinforcing data security, SDF stands as a cornerstone in scaling data infrastructures efficiently and responsibly.
SDF is in beta, and the development team is accepting design partners. Schedule a demo today to embark on the path to streamlined, secure data management.