
Overview
This blog post explores the benefits of using Pre-Commit and SQLFluff to ensure consistent, error-free SQL code. We’ll discuss how these tools can streamline SQL development and improve code quality, saving you time and helping you to work more effectively with data.
My Journey to Streamlining SQL Development
I HAD MUCH TO LEARN when I started my career as a Data Analyst. I was writing SQL to extract data from various systems, and while my queries got the job done, they could have been more consistent and well-organized. Often, I found myself writing ad-hoc queries to help decision-makers make sense of their data.
Eventually, I left my first job for a start-up, where I worked alongside other analysts and engineers. This was where I was first introduced to Git, and we contributed to a GitLab repository for version control. While the start-up had a SQL formatting guide, no checks were in place to ensure everyone adhered to it. As a result, there were inconsistencies in the SQL code that we wrote.
Fast-forward a couple of years, and I’ve discovered the power of Pre-Commit and SQLFluff. With these tools, I no longer worry about inconsistent SQL code. Pre-Commit allows me to run a set of checks on my SQL code before it is committed to the repository. SQLFluff provides automated reviews for syntax errors, indentation, and naming conventions. Now, my SQL code is consistent, well-organized, and error-free. Thanks to these tools, I can spend more time analyzing data and less time worrying about formatting and syntax.
Pre-Commit
Pre-Commit is a tool that allows developers to automate code quality checks before committing code changes. It enables developers to set up a series of checks, or “hooks,” to ensure that code meets specific standards before it is committed to the repository. Pre-Commit can be used with various programming languages, including Python, Java, and JavaScript, and easily integrated into existing workflows. By using Pre-Commit, developers can catch issues early and improve code quality.
SQLFluff
SQLFluff is a linter for SQL that helps ensure consistency and correctness in SQL code. It provides automated checks for syntax errors, indentation, and naming conventions. SQLFluff can be used with various SQL dialects, including Snowflake, Redshift, MySQL, etc.
Setup
Follow these steps to enable SQLFluff Linting via Pre-Commit in your Git Project:
Create a
.pre-commit-config.yamlfile with SQLFluff specified:# your-github-repo/.pre-commit-config.yaml default_stages: [commit, push] repos: - repo: https://github.com/sqlfluff/sqlfluff rev: 1.4.1 hooks: - id: sqlfluff-lint - id: sqlfluff-fix args: [--config, "./pyproject.toml"]Create a
pyproject.tomlfile allowing you to customize SQL Fluff Rules:# your-github-repo/pyproject.toml [tool.sqlfluff.core] dialect = "redshift" exclude_rules = "L031, L016, L034" ignore = "templating" [tool.sqlfluff.indentation] indented_joins = false indented_using_on = false [tool.sqlfluff.rules] tab_space_size = 2 [tool.sqlfluff.rules.L010] capitalisation_policy = "lower" [tool.sqlfluff.rules.L016] max_line_length = 125Install Pre-Commit by running:
pip install pre-commit
Running Tests
If you are developing new SQL for your project, Pre-Commit will test any .sql files included with the Git Commit! However, if you’d like to run tests manually before then, you could run either of the following:
# runs all linting checks
pre-commit run
# runs only linting for a specific sql file
pre-commit run sqlfluff-lint --files /path/to/your_file.sql` The checks will pass as long as your SQL meets the standards outlined in SQL Fluff!
![]()
If your SQL needs modifications, then the checks will fail.
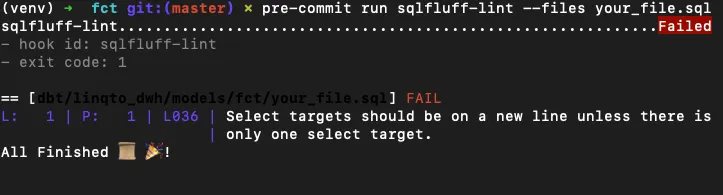
In the above failure, the check failed because of rule L036 - Select targets should be on a new line unless there is only one select target.
So after modifying the SQL, it passed!
-- your_file.sql
--fails L036
select pk_col, fk_col, col_name_one, col_name_2
from my_schema.my_table
--passes L036
select
pk_col,
fk_col,
col_name_one,
col_name_2
from my_schema.my_tableContinuous Development with Pre-Commit
To ensure the code that is committed back to your team repo meets the standards defined in Pre-Commit, you can use branch rules and GitHub workflows to run pre-commit checks before merging the code.
Pre-Commit charges for this service if the repo it’s running against is Private (a must for most organizational projects). For more information on Pre**-Commi**t costs, click here. If you are trying to avoid adding to your significant monthly software costs, use this custom GitHub workflow to set up a pre-commit check for pull requests in your private repo!
# your-github-repo/.github/workflows/pre-commit.yml
name: pre-commit
on:
- pull_request
jobs:
pre-commit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-python@v3
- name: Run pre-commit
run: |
pip install pre-commit
git fetch origin
pre-commit run --from-ref origin/${`{`} github.event.pull_request.base.ref } --to-ref ${`{`} github.event.pull_request.head.sha }Then, after this workflow has run at least once, you can add it as a required check before any PR can be merged into a protected branch. To do this in GitHub, follow these steps:
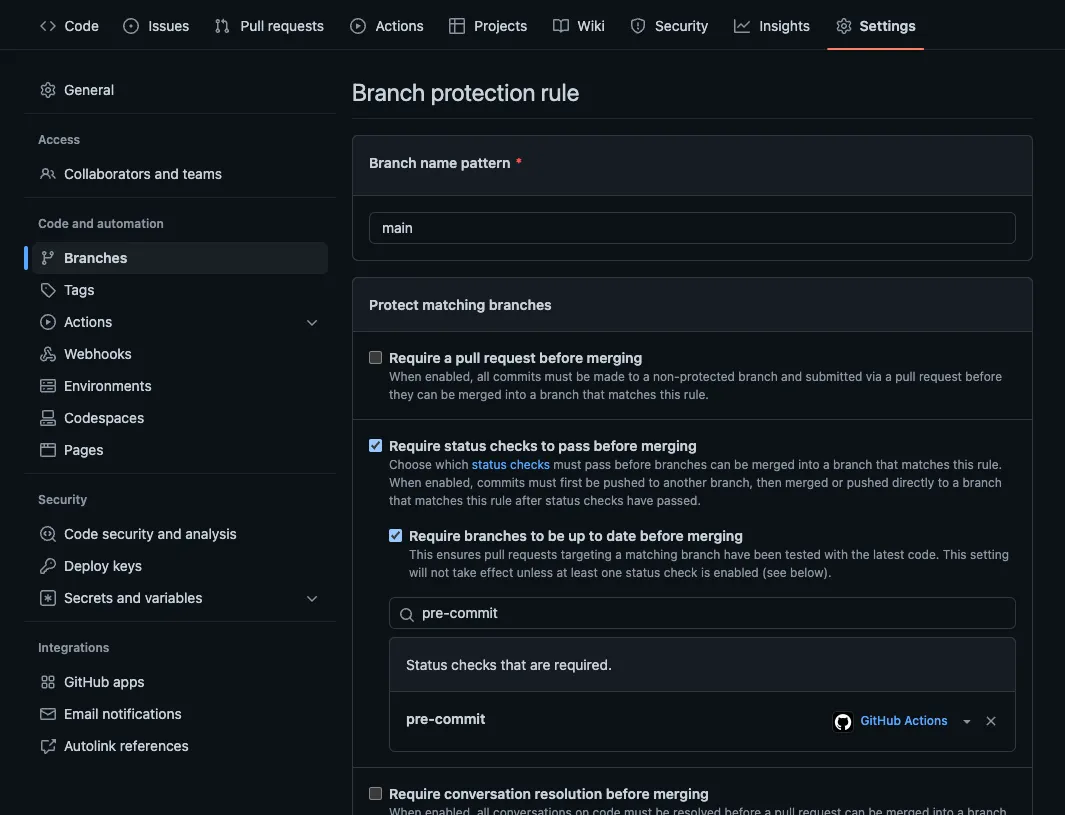
- Navigate to the
Settingstab for your repository - Under the
Code and automationsection, clickBranches - Create a new branch protection rule by clicking the
Add rulebutton - In the text box, enter the name of the branch to be protected (i.e.
main,master,prod, etc.) - Enable the check
Require status checks to pass before merging - In the search box that appears after completing step 5, search for
pre-commitand add it
Now, when a pull request is created against that branch, those checks will run automatically. This is what that looks like in the GitHub UI
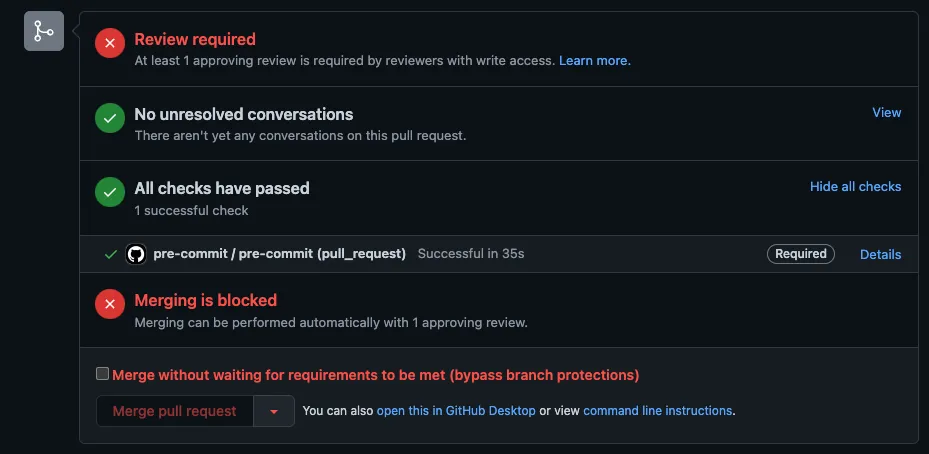
If these protection rules are enabled, it is highly recommended to enable pre-commit to catch failing checks before they are committed back to the repo. To do this, run the following commands:
cd ~/your-project-repo # make your GitHub project your current working directory
pre-commit install # enables pre-commitWhen a developer tries to make a commit, pre-commit will run automatically before the commit is successful. This ensures that any code committed passes the pre-commit check on a pull-request before it can be merged.
Summary
In conclusion, incorporating Pre-Commit and SQLFluff into my SQL development workflow has been a game-changer. These tools have helped me achieve consistent, error-free SQL code, saving valuable time and allowing me to work more effectively with data. With Pre-Commit, I can ensure that code quality checks are performed before committing changes, catching any issues early on. SQLFluff, on the other hand, acts as a powerful SQL linter, automatically reviewing my code for syntax errors, indentation, and naming conventions. The result is SQL code that is well-organized and meets the standards set by my team. By following the steps outlined in this blog post, you, too, can leverage the power of Pre-Commit and SQLFluff to streamline your SQL development process and improve code quality. Say goodbye to inconsistent and error-prone SQL code and embrace a more efficient and reliable approach to working with data.