Embarking on a data-driven journey requires powerful tools, meticulous documentation, and rigorous testing. In this guide, we delve into the heart of data engineering with Python, leveraging the capabilities of dbt (data build tool) and GitHub Workflows to optimize data quality. Join us as we uncover the key strategies for analyzing dbt model coverage, ensuring your projects are well-documented, resilient, and efficient in the dynamic landscape of data engineering.
The Problem
As my team has been developing dbt models, I’ve noticed the following issues with our metadata:
- Analytics Engineer deletes a column from their model but leaves the documentation - so the docs are out of date
- Analytics Engineer adds a new model or column(s) to an existing model, but doesn’t document it
- Analytics Engineer adds a new model or columns(s) to an existing model, but the model doesn’t have any tests
As development cycles continue, there is a high likelihood that our models’ documentation will drift until they become a massive pile of tech debt. Additionally, our small team of Analytics Engineers is under much pressure to move quickly to deliver to stakeholders. Naturally, this makes things like documentation & testing fall into a second position. I began to wonder about questions like:
- “How many of our dbt models actually have tests?”
- “Are our dbt models properly documented?”
- “How difficult would it be for them to get going if we onboarded new team members?”
The Solution
As I contemplated some of these issues, I wondered if there was a method by which we could check which columns existed in our models SQL and if we could compare them to the dbt project YAML to determine if they were documented and tested accordingly. There’s a package that can parse SQL to return the resulting columns called SQLGlot! So, anyway, I started hacking.

Ultimately, what I landed on was this Python Script. This script allows you to check coverage for one SQL model or an entire project (depending on which args you pass to it). So I grabbed dbt’s classic Jaffle Shop project to test it out. By the way, I’ve embedded the jaffle shop in an Airflow project and have it running natively in Airflow using the Astronomer Cosmos project. This Airflow project can be found here. However, to navigate the lay of the land, here is my project tree:
.
├── Dockerfile
├── Makefile
├── dags
│ ├── basic_cosmos_task_group.py
│ ├── dbt
│ │ └── cosmos_jaffle_shop # the Jaffle Shop project
│ │ ├── README.md
│ │ ├── dbt_project.yml
│ │ ├── models
│ │ ├── seeds
│ │ └── target
│ └── utils
│ └── dbt
│ └── custom_operators.py
├── docker-compose.yaml
├── plugins
├── requirements
│ ├── dev-requirements.txt
│ └── requirements.txt
├── tests
│ ├── model_coverage.py
│ └── requirements.txt
└── README.md
So that script that I referenced earlier is in ./tests/model_coverage.py. If we run that from the root of our project like so:
$ python ./tests/model_coverage.py --project_dir ./dags/dbt/cosmos_jaffle_shop
| Model | Tbl Doc | Column Docs | Test |
|-----------------------|-----------|---------------|--------|
| models.customers | ✔ | 85.71% | ✔ |
| models.orders | ✔ | 100.0% | ✔ |
| staging.stg_customers | ✘ | 0.0% | ✔ |
| staging.stg_payments | ✘ | 0.0% | ✔ |
| staging.stg_orders | ✘ | 0.0% | ✔ |
---MODELS.CUSTOMERS COLUMN DISCREPANCIES---
The following columns don't exist in SQL and can be removed from properties.yml:
- total_order_amount
The following columns are completely missing in the properties.yml:
- customer_lifetime_value
---STAGING.STG_CUSTOMERS COLUMN DISCREPANCIES---
The following columns are completely missing in the properties.yml:
- first_name
- last_name
The following columns are missing descriptions in properties.yml:
- customer_id
---STAGING.STG_PAYMENTS COLUMN DISCREPANCIES---
The following columns are completely missing in the properties.yml:
- order_id
- amount
The following columns are missing descriptions in properties.yml:
- payment_id
- payment_method
---STAGING.STG_ORDERS COLUMN DISCREPANCIES---
The following columns are completely missing in the properties.yml:
- customer_id
- order_date
The following columns are missing descriptions in properties.yml:
- order_id
- status
As you can see, it scans the .sql files in the ./dags/dbt/cosmos_jaffle_shop/models directory and gives a full report on each model. Including a list of columns that are:
- missing descriptions
- missing from the YAML altogether
- can be removed from the YAML because it no longer exists in the SQL
Alternatively, we can run the script for just one or two models by using the --filtered_models argument, like so:
# Runs the coverage report for just the orders & customers models
python ./tests/model_coverage.py --project_dir ./dags/dbt/cosmos_jaffle_shop --filtered_models "orders customers"
| Model | Tbl Doc | Column Docs | Test |
|------------------|-----------|---------------|--------|
| models.customers | ✔ | 85.71% | ✔ |
| models.orders | ✔ | 100.0% | ✔ |
---MODELS.CUSTOMERS COLUMN DISCREPANCIES---
The following columns don't exist in SQL and can be removed from properties.yml:
- total_order_amount
The following columns are completely missing in the properties.yml:
- customer_lifetime_value
CICD Implementation
After building this script, I wanted it to work as a GitHub action. Specifically, I wanted it to:
- Run if a
.sql file in the models directory changed in a PR
- Run the Python script only for the models that were being changed
- Output the coverage results to a comment on the PR automatically.
Sure enough, I landed on this GitHub Action:
name: model-coverage
on:
pull_request:
paths:
- 'dags/dbt/cosmos_jaffle_shop/models/**.sql'
jobs:
model-coverage:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-python@v3
- name: Get Changed dbt Model Names
run: |
git fetch origin
CHANGED_MODELS=$(git diff --name-only origin/$ $ | grep -E 'dags/dbt/cosmos_jaffle_shop/models/.*\.sql$' | awk -F'/' '{print $NF}' | sed 's/\.sql$//' | tr '\n' ' ')
echo "CHANGED_MODELS=$CHANGED_MODELS" >> $GITHUB_ENV
- name: Install Python Packages
run: |
python -m pip install --upgrade pip
pip install -r ./tests/requirements.txt
- name: Run Coverage Script
id: run-script
run: |
python ./tests/model_coverage.py --project_dir ./dags/dbt/cosmos_jaffle_shop --filtered_models "$CHANGED_MODELS"
env:
CHANGED_MODELS: $
- name: Comment on PR with the captured output
uses: actions/github-script@v6
with:
script: |
github.rest.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: `$`
})
ERROR TROUBLESHOOTING: If you run into the error Resource not accessible by integration error like I did, ensure that you give Workflow write permissions to your repo (see steps to do that here).
With this in place, when one of my team’s Engineers opens a PR to add a new or change an existing model, the script will automatically run, giving us a coverage report on model documentation and data quality covearge:
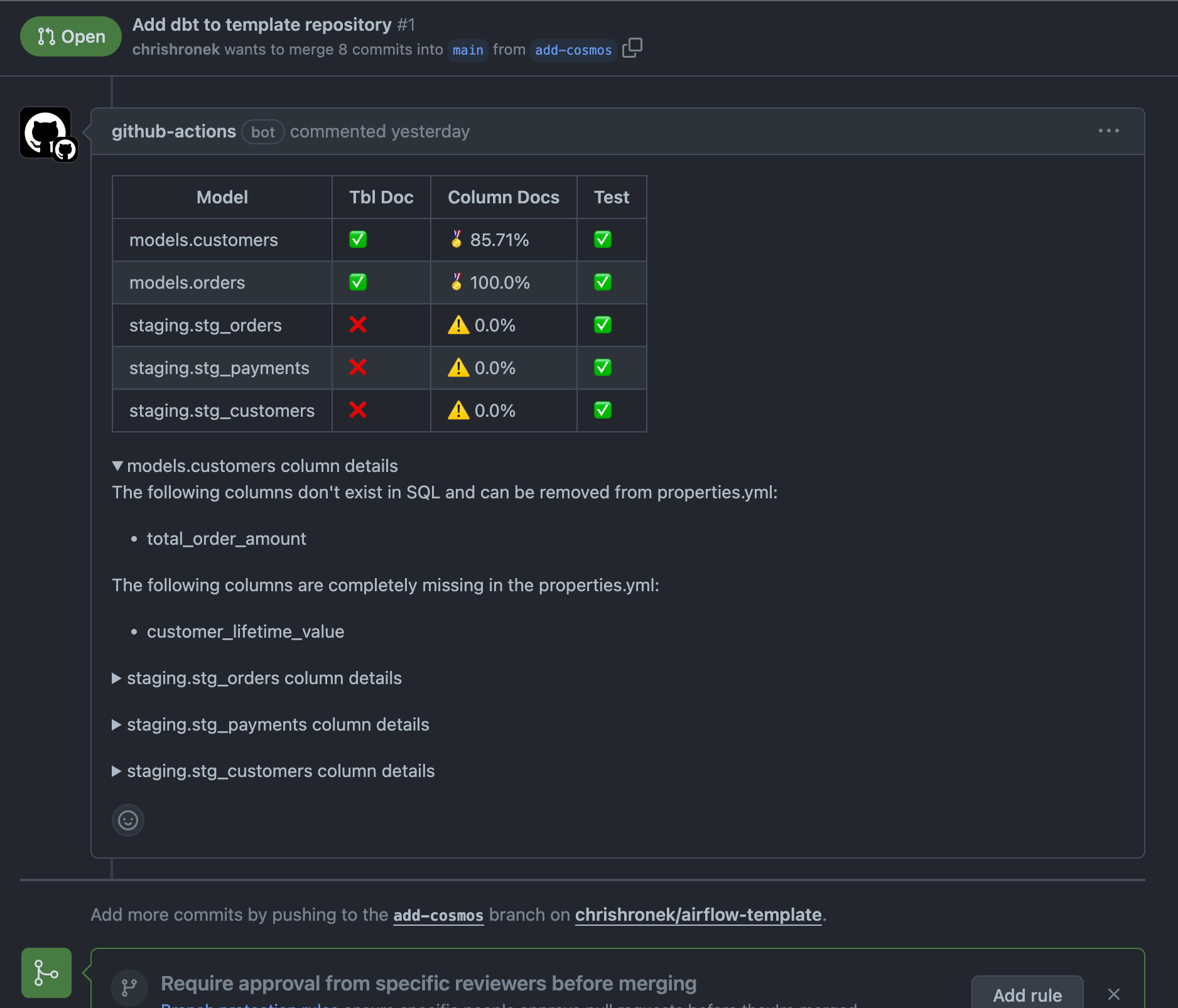
We can apply the recommendations from the comment. Let’s add some definitions to the columns and push them to the PR.
# ./dags/dbt/cosmos_jaffle_shop/models/staging/schema.yml
- name: stg_orders
description: "The raw untransformed table of customer orders"
columns:
- name: order_id
description: "The Unique Identifier for an order"
tests:
- unique
- not_null
- name: customer_id
description: "The unique identifier for the customer who made the order"
- name: order_date
description: "The date the order was initially placed"
- name: status
description: |
The order's current state can be any of the following:
- placed: Customer has placed the order and is pending shipment
- shipped: Order is in transit
- completed: Order has been delivered
- return_pending: Customer has initiated a return of the order
- return: Order return has been completed
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
After adding the column and table descriptions, notice the improvement in our coverage report:
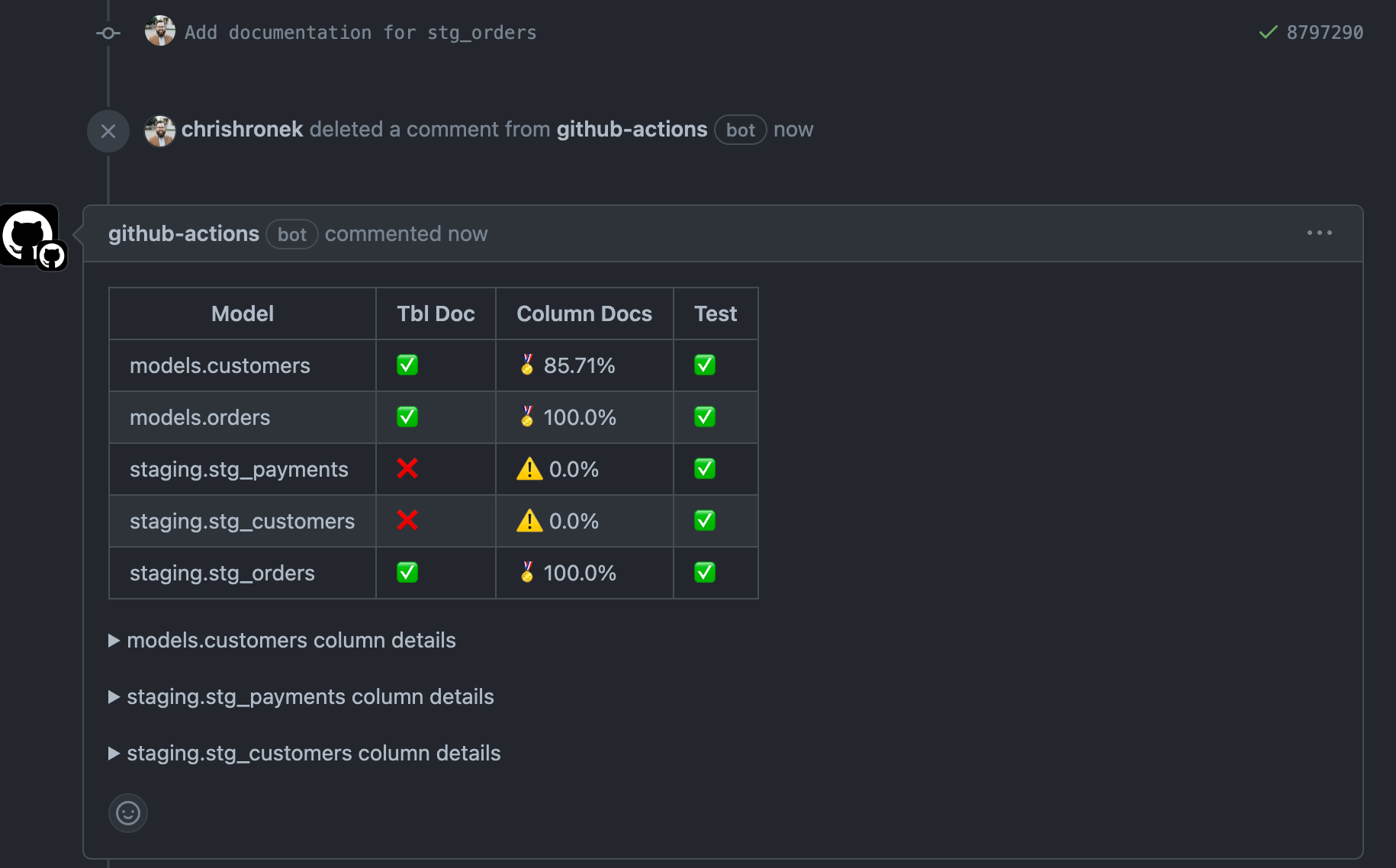
The stg_orders model now has 100% description coverage! Luckily, all our models have at least one column with a data quality test. Otherwise, the Test column would show an ‘X’ instead of a Checkmark.
Script Shortcomings and Assumptions
This Python script will NOT work perfectly with any dbt project, but it should serve as your starting point. Here are some things to consider:
- You cannot use
* in the resulting SQL query for your model (using an asterisk in CTEs is fine, just not the final SQL statement)
- Jinja templating is a mess; I wrote a method to handle the common dbt functions – but you’ll need to potentially add to it for your dbt project variables, macros, etc. See the parse_sql method in my linked script.
- This script was quick and dirty and can probably be optimized/simplified – that being said, all recommendations are welcome
- dbt does have a similar package to this script dbt-coverage, however it assumes that you have a manifest.json file already pre-generated where my script deosn’t require a connection to your data warehouse.
- For my
parse_sql step mentioned in the second bullet above, we could change the function to run a dbt compile command to generate the SQL and resolve the Jinja. However, that would require a connection to our data warehouse (which I just wanted to avoid). However, for those that are okay with that - you could start with something like this.
Conclusion
In conclusion, our guide navigates the challenges of optimizing data quality in data engineering projects through a Python-powered approach leveraging dbt and GitHub Workflows. By comparing SQL files to project YAML, the solution reveals discrepancies, offering insights into the testing and documentation status of dbt models. Integrated into GitHub Actions for seamless CI/CD, the script provides automatic coverage reports on pull requests, fostering an iterative improvement process. While the solution is adaptable, its effectiveness depends on project-specific considerations, offering a flexible foundation for enhancing data quality in the dynamic landscape of data engineering projects.
Need Help?
If you are looking to improve your Data Quality or Data Catalog or are in search of other Data Consultancy services for your business, please reach out to us on Discord or submit a service request here.





{kind=link}